在【LLM】LLM 中增量解碼與模型推理解讀一文中對 LLM 常見名詞進(jìn)行了介紹,本文會對 LLM 中評價(jià)指標(biāo)與訓(xùn)練概要進(jìn)行介紹,本文并未介紹訓(xùn)練實(shí)操細(xì)節(jié),未來有機(jī)會再了解~
一、LLM 如何停止輸出
在看 LLM 評價(jià)指標(biāo)前,先看看 LLM 如何停止輸出。
模型生成特殊終止符(如 DeepSeek R1 MoE 中 ID 為 1 的 token)表示回答完成。
...在物理學(xué)領(lǐng)域做出了革命性貢獻(xiàn)。[EOS]
最大長度限制 預(yù)設(shè)生成 token 上限(常見值:512/1024/2048),防止無限生成,保障系統(tǒng)資源安全。
停止詞 / 序列觸發(fā) 設(shè)置 “\n\n”“###” 等符號為停止信號,強(qiáng)制結(jié)束生成(適用于格式控制)。
內(nèi)容智能判斷
重復(fù)檢測:識別循環(huán)或冗余內(nèi)容時(shí)自動終止。
語義完整性:當(dāng)回答覆蓋查詢所有維度(如時(shí)間、影響)時(shí)停止。
停止機(jī)制建議組合使用(如 EOS + 最大長度),確保生成既完整又可控。
綜合來看,Decode 階段的循環(huán)機(jī)制是大模型實(shí)現(xiàn)長文本生成的核心:
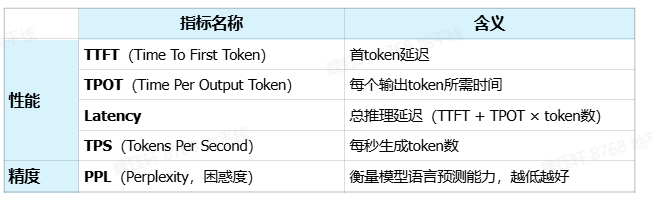
二、LLM 評價(jià)指標(biāo)
常見 LLM 評價(jià)指標(biāo)如下:
三、LLM 訓(xùn)練概要
本節(jié)主要參考: https://zhuanlan.zhihu.com/p/719730442 https://zhuanlan.zhihu.com/p/1912101103086043526
數(shù)據(jù)準(zhǔn)備:喂給模型“知識”
收集數(shù)據(jù):從互聯(lián)網(wǎng)、書籍、論文等獲取海量文本(如英文維基百科+書籍+網(wǎng)頁)。
清洗數(shù)據(jù):過濾垃圾、重復(fù)內(nèi)容、有害信息,保留高質(zhì)量文本。
分詞(Tokenization):把文本拆成“詞語片段”(如用 Byte-Pair Encoding 或 SentencePiece)。
模型設(shè)計(jì):搭建“大腦”結(jié)構(gòu)
預(yù)訓(xùn)練(Pre-training):自主學(xué)習(xí)語言規(guī)律
微調(diào)(Fine-tuning):定向優(yōu)化能力 場景化訓(xùn)練:用特定任務(wù)的數(shù)據(jù)(如客服對話、醫(yī)療問答)進(jìn)一步優(yōu)化模型。
評估與部署:測試和落地
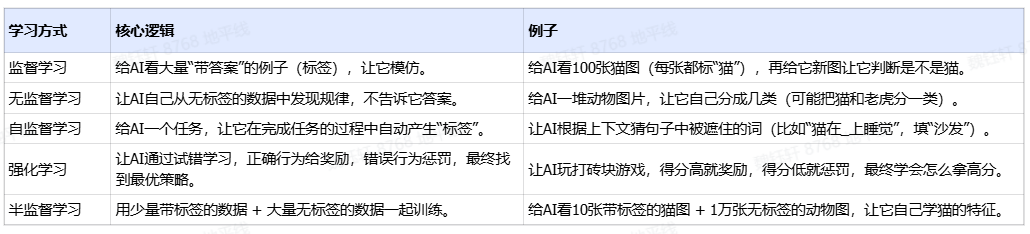
四、LLM 中學(xué)習(xí)策略
在上面的訓(xùn)練過程中,提到了“自監(jiān)督學(xué)習(xí)"、"強(qiáng)化學(xué)習(xí)”這幾個(gè)概念。這些都屬于大模型訓(xùn)練過程中的學(xué)習(xí)策略或者叫學(xué)習(xí)范式,以下是對不同學(xué)習(xí)策略的總結(jié)和對比:
監(jiān)督學(xué)習(xí)的標(biāo)簽是人工標(biāo)注的,這是 CNN 這些架構(gòu)訓(xùn)練模型或算法很常見的方法。標(biāo)注的意思就是我們喂給模型的數(shù)據(jù)會被人工提前標(biāo)注出特征點(diǎn),比如我們會給很多圖片中的汽車做出標(biāo)記,目的是告訴大模型我們打標(biāo)簽的這些圖形就是汽車,讓大模型記住它。
強(qiáng)化學(xué)習(xí)不需要大量的人工標(biāo)注,只是需要設(shè)計(jì)一個(gè)獎(jiǎng)勵(lì)函數(shù),設(shè)計(jì)好獎(jiǎng)勵(lì)規(guī)則,當(dāng)模型給出的結(jié)果是接近目標(biāo)值的,我們就給一個(gè)正反饋或者高的分?jǐn)?shù)。
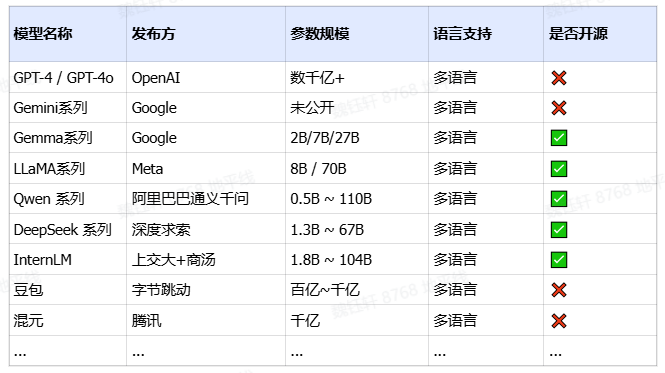
五、常見 LLM 模型
六、LLM 的挑戰(zhàn)與展望
6.1 挑戰(zhàn)
幻覺現(xiàn)象(Hallucination):生成看似合理但事實(shí)錯(cuò)誤的內(nèi)容。
推理成本高:內(nèi)存與計(jì)算資源消耗大,部署成本高昂。
推理速度慢:長文本響應(yīng)延遲顯著影響用戶體驗(yàn)。
數(shù)據(jù)安全與偏見問題:訓(xùn)練數(shù)據(jù)中可能包含歧視或敏感信息。
6.2 展望
文本生成:自動撰寫新聞、故事、詩歌。
翻譯系統(tǒng):多語言互譯,甚至語音到文本。
情緒分析:用于品牌情感監(jiān)測、影評判斷。
對話機(jī)器人:如 ChatGPT,提供自然流暢的對話能力。
代碼生成:輔助編程任務(wù),生成/解釋代碼。
近年來也發(fā)展出支持圖像、語音、視頻等多模態(tài)輸入的 VLM(Vision-Language Models)和 VLA(Vision-Language-Action),可以研究學(xué)習(xí)的地方非常多。
后續(xù)會轉(zhuǎn)到 VLM 的學(xué)習(xí)~