用英特爾? 酷睿? Ultra及OpenVINO? GenAI本地部署DeepSeek-R1

DeepSeek-R1在春節期間引發了全球科技界的熱度,DeepSeek-R1 是由 DeepSeek 開發的開源推理模型,用于解決需要邏輯推理、數學問題解決和實時決策的任務。使用 DeepSeek-R1,您可以遵循其邏輯,使其更易于理解,并在必要時對其輸出提出質疑。此功能使推理模型在需要解釋結果的領域(如研究或復雜決策)中具有優勢。AI 中的蒸餾從較大的模型創建更小、更高效的模型,在減少計算需求的同時保留了大部分推理能力。DeepSeek 應用了這項技術,使用 Qwen 和 Llama 架構從 R1 創建了一套提煉的模型。這使我們能夠在普通筆記本電腦上本地試用 DeepSeek-R1 功能。在本教程中,我們將研究如何使用 OpenVINO? 運行 DeepSeek-R1 蒸餾模型。
本文將基于OpenVINO? GenAI庫,介紹使用三行Python代碼,將DeepSeek-R1模型部署到英特爾酷睿Ultra CPU、GPU或NPU的完整過程。
◆ 趕緊在本地運行與OpenAI-o1能力近似的DeepSeek-R1模型
https://mp.weixin.qq.com/s/Nu6ovClNOAfhXa-exnlWdg
◆ OpenVINO? GenAI庫
https://mp.weixin.qq.com/s/1nwi3qJDqAkIXnrGQnP3Rg
1 硬件介紹
本文是用KHARAS深圳市世野科技提供基于英特爾酷睿Ultra的AI PC,只有435g, 以下為其參數:

主要特點
o Intel? Core? Ultra Processor Series 2
o AI Performance: up to 115 TOPS
o NPU: 4.0 AI Engine, up to 47 TOPS
o GPU: Intel? Arc? 140V, up to 64 TOPS
o 32GB LPDDR5X Memory, 1TB PCIe SSD
o Copilot+ PC: Windows AI assistant
o Battery Life Optimization
o WiFi+ Bluetooth: AX211D2
應用場景
o AI PC 開發:以 AI 為中心的硬件和軟件的進步使 AI 在 PC 上成為可能。將項目從早期 AI 開發無縫過渡到基于云的訓練和邊緣部署。
o 多個處理器中的 AI 加速:英特爾? 酷睿? Ultra 7 258V 處理器通過混合架構將 CPU、GPU 和 NPU 相結合,并通過高帶寬內存和緩存進行增強,從而加速 AI。
o Intel AI PC 開發支持:通過針對 Intel CPU 和 GPU 優化的 OpenVINO? 工具包和 ONNX 運行時獲得 Intel 官方支持。
2 什么是OpenVINO? GenAI庫?
回到標題, 我們將用OpenVINO? GenAI庫基于OpenVINO? 工具套件和運行時,提供C++/Python API,支持生成式AI模型在英特爾? 硬件平臺上快速部署。
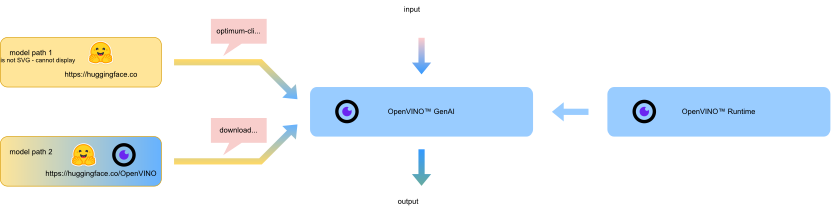
◆ OpenVINO? GenAI庫
https://mp.weixin.qq.com/s/1nwi3qJDqAkIXnrGQnP3Rg
◆ OpenVINO? 工具套件
https://mp.weixin.qq.com/s/fORowUzzcPSVIO6AieoUKA
◆ Github倉:https://github.com/openvinotoolkit/openvino.genai
3 搭建OpenVINO? GenAI開發環境
只需兩條安裝命令,即可完成OpenVINO? GenAI開發環境的搭建:
# 安裝OpenVINO GenAI pip install openvino-genai # 安裝optimum-intel,用于轉換并量化生成式AI模型 pip install pip install optimum-intel[openvino]
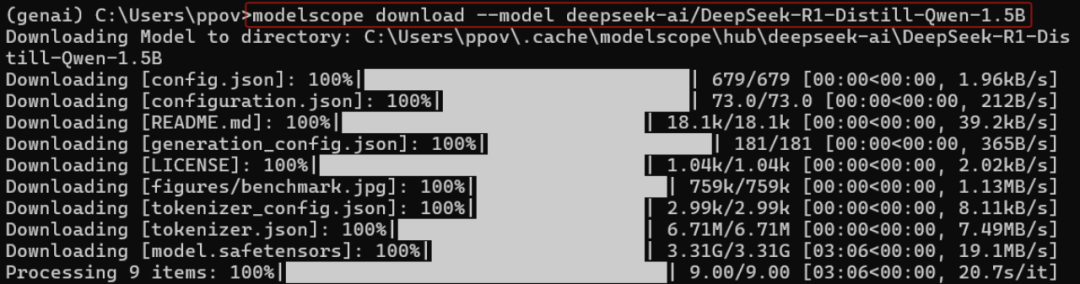
4下載并量化DeepSeek-R1模型
請先使用下面的命令,從ModelScope下載DeepSeek-R1-Distill-Qwen-1.5B模型到本地:
# 安裝ModelScope pip install modelscope # 下載DeepSeek-R1-Distill-Qwen-1.5B模型 modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
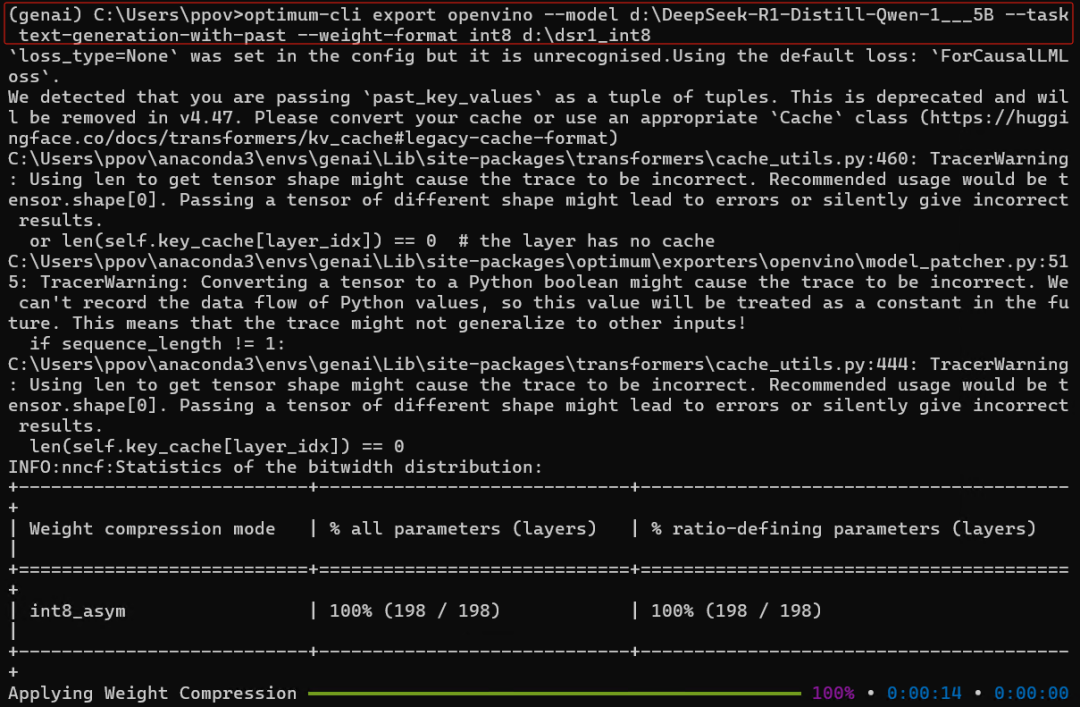
5 使用 Optimum-CLI 工具轉換模型
本文使用optimum-intel命令,將DeepSeek-R1-Distill-Qwen-1.5B PyTorch格式模型轉換為OpenVINO? IR格式模型,并完成FP16、INT8或INT4量化。
Optimum Intel 是 Transformers 和 Diffusers 庫與 OpenVINO? 之間的接口,用于加速 Intel 架構上的端到端管道。它提供易于使用的 cli 界面,用于將模型導出為 OpenVINO? 中間表示 (IR) 格式。
以下命令演示了使用 optimum-cli 導出模型的基本命令
optimum-cli export openvino --model--task <任務>
其中 --model 參數是 HuggingFace Hub 中的模型 ID 或帶有 model 的本地目錄(使用 .save_pretrained 方法保存),--task 是 導出的模型應該解決的支持任務之一。對于 LLM,建議使用 text-generation-with-past。如果模型初始化需要使用遠程代碼,則應額外傳遞 --trust-remote-code 標志。
optimum-cli export openvino --model d:DeepSeek-R1-Distill-Qwen-1___5B --task text-generation-with-past --weight-format int4 --group-size 128 --ratio 0.8 --sym d:dsr1_int4 optimum-cli export openvino --model d:DeepSeek-R1-Distill-Qwen-1___5B --task text-generation-with-past --weight-format int8 d:dsr1_int8 optimum-cli export openvino --model d:DeepSeek-R1-Distill-Qwen-1___5B --task text-generation-with-past --weight-format fp16 d:dsr1_fp16
設置 --weight-format 分別為 fp16、int8 或 int4。這種類型的優化可以減少內存占用和推理延遲。默認情況下,int8/int4 的量化方案是非對稱的,要使其對稱化,您可以添加 --sym。
對于 INT4 量化,您還可以指定以下參數:
--group-size 參數將定義用于量化的組大小,-1 將導致每列量化。
--ratio 參數控制 4 位和 8 位量化之間的比率。如果設置為 0.9,則意味著 90% 的層將被量化為 int4,而 10% 的層將被量化為 int8。
較小的 group_size 和 ratio 值通常會以犧牲模型大小和推理延遲為代價來提高準確性。您可以使用 --awq 標志啟用在模型導出期間以 INT4 精度額外應用 AWQ,并使用 --datasetparameter 提供數據集名稱(例如 --dataset wikitext2)
注意:
1. 應用 AWQ 需要大量的內存和時間。
2. 模型中可能沒有匹配的模式來應用 AWQ,在這種情況下,將跳過它。
6 編寫DeepSeek-R1的推理程序
獲得DeepSeek-R1的OpenVINO? IR模型后,即可使用OpenVINO? GenAI庫編寫推理程序,僅需三行Python代碼,如下所示:
import openvino_genai
#Will run model on CPU, GPU or NPU are possible options
pipe = openvino_genai.LLMPipeline("D:dsr1_int4", "GPU")
print(pipe.generate("Prove the Pythagorean theorem.", max_new_tokens=4096))7 總結
使用OpenVINO? GenAI庫可以方便快捷的將生成式AI模型本地化部署到英特爾? 酷睿? Ultra CPU、GPU或NPU上。
參考文獻:
https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/notebooks/deepseek-r1/deepseek-r1.ipynb






評論