美媒:人工智能實現“聞聲識人” 但遠未達到完美

美媒稱,人工智能(AI)現在可以做到只參考一小段音頻,就能生成一個人面部的數字圖像。
據美國趣味科學網站6月11日報道,科學家用網上數百萬段教學視頻,對這種名為“講話到面孔”的神經網絡——以類似人腦方式“思考”的計算機——進行了訓練,視頻內容是10萬多個不同面孔講話的場景。
研究人員在一項新的研究結果中寫道,通過這些數據集,“講話到面孔”掌握了聲音信息與人臉某些特征之間存在的關聯。然后,人工智能會利用一段音頻來塑造與語音匹配的擬真面孔。
這一研究結果5月23日發表在阿奇夫論文預印本網站上,尚未接受同行評議。
報道稱,值得慶幸的是,人工智能(尚)不能僅憑一個人的聲音就知道他到底長什么樣。研究報告的撰寫者說,該神經網絡會識別講話中指向性別、年齡和種族的一些標記,這些特征是許多人共有的。
科學家在研究報告中寫道:“如此一來,該模型只會形成普通長相的面孔。它不會形成特定個人的形象。”
人工智能已經證明,它可以生成準確度高得驚人的人臉,不過坦率地講,它所塑造的貓臉有點恐怖。
報道稱,“講話到面孔”生成的人臉——都是面朝前方,沒什么表情——與聲音背后的人并不嚴格匹配。不過研究結果表明,它生成的形象確實經常捕捉到了講話者正確的年齡段、種族和性別。
然而,這種算法對聲音信息的解讀還遠未達到完美。在面對不同的語言時,“講話到面孔”表現得好壞參半。例如,人工智能在聽了一段亞洲人講中文的音頻后,相關程序形成了一個亞洲人的面孔。然而,據科學家說,當同一個人在另一段音頻中用英語說話時,人工智能生成了一個白人的面孔。
該算法還顯示出性別上的偏見,將低沉的聲音與男性面孔聯系起來,將尖細的嗓音與女性面孔聯系起來。研究人員在報告中寫道,由于用來訓練人工智能的數據集只是YouTube網站上的教學視頻,因此“不能代表全世界的人口”。


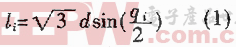





評論