基于單片機的智能終端中漢字顯示的處理

字模裁減及填充終端字庫下載文件流程如圖4 所示:
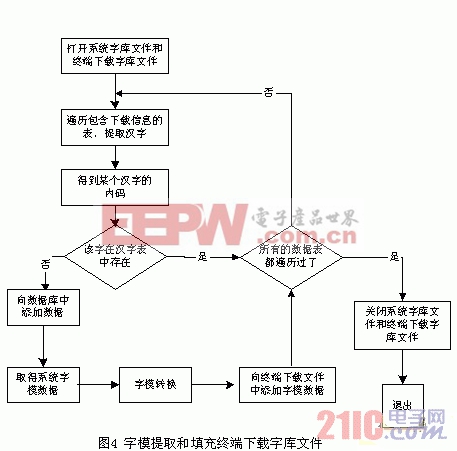
首先,運行在服務器上的處理程序遍歷數據庫中的菜譜表、桌位表等所有包含下載信息的、帶有漢字的表記錄。從中找到需要下載的漢字,根據這些漢字的內碼,從系統字庫中得到漢字的字模,經過字模轉化(在后面介紹),然后保存在字庫下載文件中。
為了保證下傳的漢字字模不會重復,在數據庫中創建一個“漢字表”來存儲每個經過篩選的漢字的信息。表中有兩個字段,一個用來存儲漢字的內碼,另一個用來存儲該漢字字模在字庫下載文件中的偏移地址(終端程序可以通過某個漢字在字庫下載文件中的偏移地址來唯一確定該漢字的字模存放位置)。每得到一個漢字的內碼時,先到漢字表中查詢表中是否已經包含了該漢字,再決定是否進行提取和下載處理。
然后,處理程序逐個遍歷菜譜表、桌位表等數據表項來生成菜譜下載文件、桌位下載文件等。這些下載文件中涉及到的漢字,以該漢字的字模在終端下載字庫文件中的偏移地址來標識。這樣每個漢字可以用兩個字節唯一標識。
最后,處理程序將以上這些下載文件通過串口下傳給終端,終端將下載文件的內容保存在數據存儲區中,并記錄存放字庫下載文件數據區的起始地址,記為A。當需要顯示漢字時,終端程序先得到該漢字在下載文件中的偏移地址,記為B,然后計算出該漢字字模的存放位置(A+B),從此位置開始連續讀取32字節,就得到了該漢字字模數據,之后通過驅動液晶屏將漢字顯示出來。
3.需要注意的關鍵技術
3.1 漢字字模的提取
先說明一下在中文信息交換標準GB2312中涉及到的三個概念:區位碼、國標碼、內碼。
中文國標字符集是一個94×94的矩陣,其中每一個漢字(包括數字、英文字母和標點符號)都是二維矩陣中的某個元素。這樣,每一個漢字都可以用一個二元組來表示(x,y)。其中,x是該字所在的行號,y為列號。








評論