中國芯片與摩爾定律

本周二,拜登政府收緊了對銷往中國的先進人工智能(AI)芯片的出口管制;主要目標是英偉達(Nvidia)的 H800 和 A800 芯片,這些芯片是專門為規避去年實施的控制而設計的。H800/A800 和 H100/A100 之間的主要區別在于它們的通信帶寬:A100 具有 600 Gb/s 的速度(H100 具有 900GB/s),這恰好是去年出口管制所禁止的限制,A800 和 H800 的通信速度僅限于 400 Gb/s。
本文引用地址:http://www.czjhyjcfj.com/article/202310/451870.htm通信速度之所以重要,與 Nvidia 首席執行官黃仁勛 (Jensen Huang) 的論點「摩爾定律已死」有關。摩爾定律最初于 1965 年提出,指出集成電路中晶體管的數量每年都會增加一倍。十年后,戈登·摩爾將他的預測修正為每兩年翻一番,直到過去十年左右,這一預測才放緩至大約每三年翻一番。
但在實踐中,摩爾定律已經變得更類似于科技行業的基本法則:隨著時間的推移,計算能力將會增加,而且會變得更便宜。這一原則與戈登·摩爾的技術預測相關:較小的晶體管可以更快地切換,并且在切換時使用更少的能量,即使更多的晶體管可以集成在單個晶圓上;這意味著您可以在每個晶圓上獲得更多芯片或更大的芯片,從而降低價格或以相同的價格提高功率。在實踐中我們兩者都得到了。
至關重要的是,科技行業的其它公司不需要了解摩爾定律的技術或經濟細節:60 年來,簡單地假設計算機會變得更快是安全的,這意味著最佳方法始終是專為尖端或超越而構建,并相信處理器速度能夠趕上您的使用案例。
摩爾定律終結?
近幾年,英偉達首席執行官黃仁勛一再宣稱摩爾定律已死。從技術角度來看,速度確實放緩了,但密度在持續增加。以下是臺積電按制程節點尺寸劃分的晶體管密度,以每個節點尺寸的第一代工藝為例。
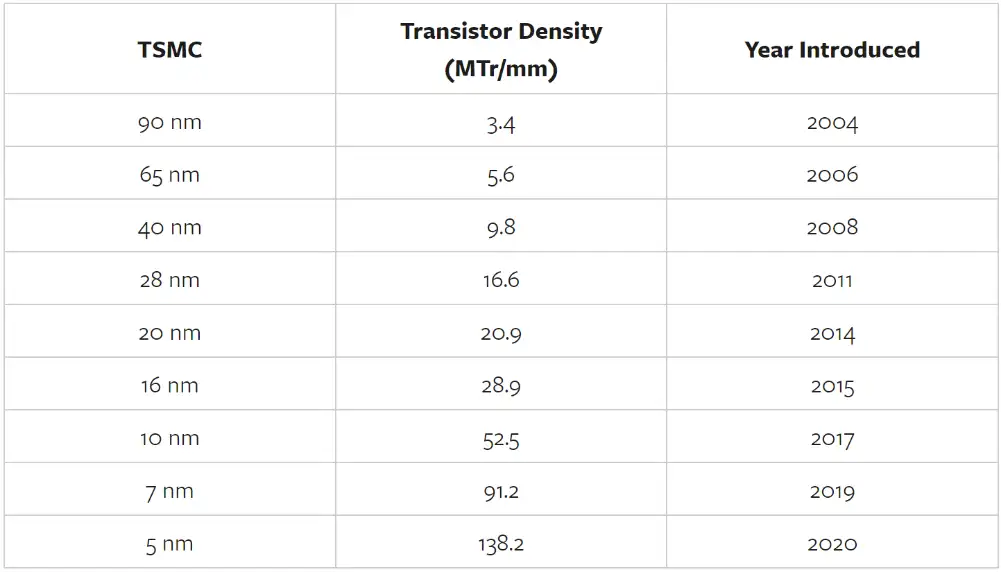
請記住,成本很重要,以下是臺積電每晶圓介紹價格的同一張表,以及每十億個晶體管的價格:
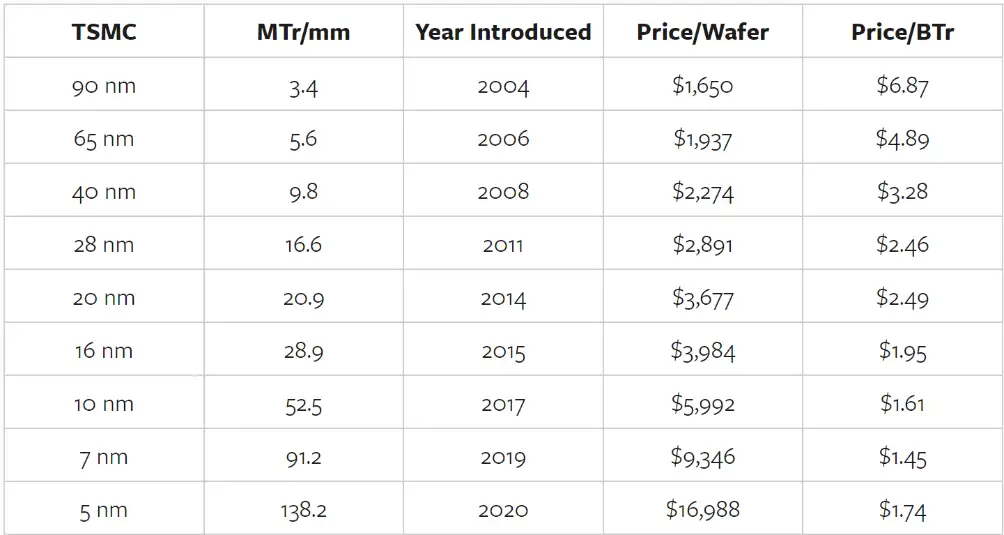
請注意右下角的數字:采用臺積電的 5 nm 工藝,每個晶體管的價格上漲了,而且上漲了很多 (20%)。原因很明顯:5nm 是第一個需要 ASML 極紫外 (EUV) 光刻技術的工藝,而 EUV 機器非常昂貴——每臺約 1.5 億美元。換句話說,雖然摩爾定律的技術定義將繼續存在,但芯片總是變得更快、更便宜的原則卻不會繼續存在。
GPU 和令人尷尬的并行性
需要明確的是,黃仁勛的論點并不僅僅基于 5nm 芯片的成本,摩爾定律涉及速度和成本,而事實是,隨著能源成為從移動設備到個人電腦再到數據中心的所有設備的限制,許多密度增益主要用于提高電源效率。黃仁勛多年來的論點是,Nvidia 擁有提高計算速度的解決方案:使用 GPU。
GPU 比 CPU 簡單得多;這意味著它們可以更快地執行指令,但這些指令必須更簡單,可以同時運行許多它們以獲得巨大的結果。不出所料,圖形是最明顯的例子:每個「著色器」——GPU 的主要處理組件——計算將在屏幕的單個部分上顯示的內容,該部分的大小是可用著色器數量的函數。如果您有 1024 個著色器,則每個著色器繪制屏幕的 1/1024。因此,如果您有 2048 個著色器,則繪制屏幕的速度可以提高兩倍。圖形性能是「令人尷尬的并行」,也就是說它隨著解決問題的處理器數量而變化。
這種「令人尷尬的并行性」是 GPU 相對于 CPU 具有超強性能的關鍵,但挑戰在于并非所有軟件問題都可以輕松并行化;Nvidia 的 CUDA 生態系統旨在提供工具來構建可以利用 GPU 并行性的軟件應用程序,并且是鞏固 Nvidia 主導地位的主要護城河之一,但大多數軟件應用程序仍然需要 CPU 才能運行。
事實證明,無論是在訓練模型還是在推理模型方面,人工智能都是一個令人尷尬的并行應用程序。此外,最佳的可擴展性遠遠超出了計算機顯示器顯示圖形的范圍。這就是為什么 Nvidia AI 芯片具有芯片禁令所提到的高速互連功能:AI 應用程序同時在多個 AI 芯片上運行,但確保這些 GPU 繁忙的關鍵是向它們提供數據,而這需要那些高速互連。
話雖如此,我對傳統數據中心應用程序大規模轉向 GPU 持懷疑態度。
基于 CPU 的應用程序不僅更容易開發,而且大多已經構建完成。我很難想象哪些公司會花費時間和精力將已經在 CPU 上運行的東西移植到 GPU 上;歸根結底,在云中運行的應用程序是由提供云資源需求的客戶決定的,而不是尋求優化 FLOP/rack 的云提供商。
認為傳統 CPU 仍有一定生命力的另一個原因是:事實證明摩爾定律可能又回到了正軌。
EUV 和摩爾定律
上文所示表格只跑到 5nm,iPhone 15 Pro 采用的是 N3 芯片,以下為相應的價格/晶體管表。
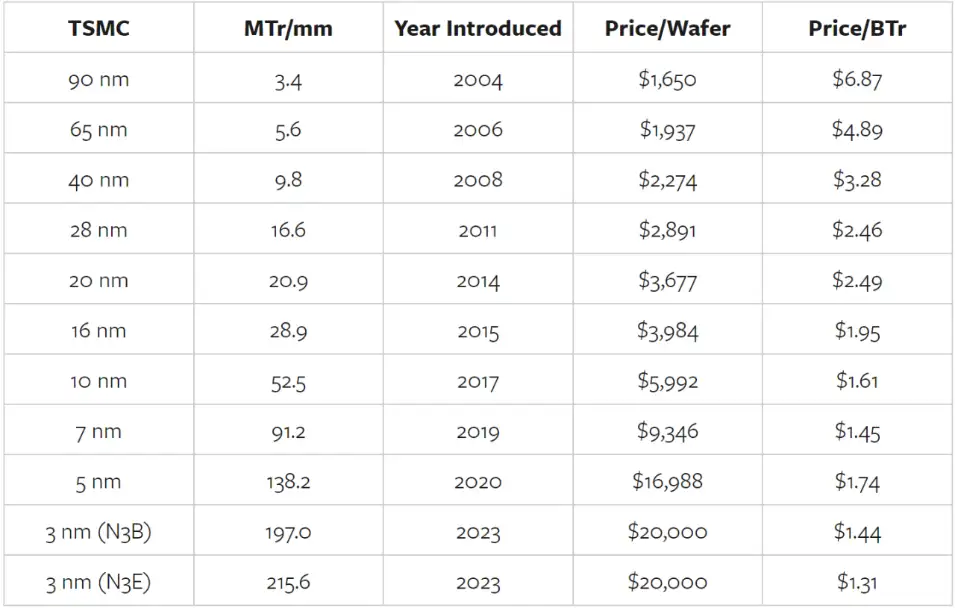
雖然我之前只給出了每個節點的第一個版本,但用于 iPhone A17 Pro 芯片的 N3B 工藝是一個死胡同;臺積電改變了 N3E 的做法,這將成為未來 N3 系列的基礎。這也使得 N3 在每晶體管價格方面的飛躍更加令人印象深刻:N3B 消除了 5nm 的倒退,N3E 比 7nm 有了顯著的改進。
此外,EUV 機器成本很高,但摩爾定律中的價格下降并不是設備變得更便宜的結果。請注意,每片晶圓的價格一直在不斷上漲。相反,不斷下降的價格/晶體管是摩爾定律的函數,也就是說,EUV 等新設備讓我們「將更多元件填充到集成電路上」。
5nm 發生的情況與 20nm 每晶體管價格上漲的情況類似:那是臺積電開始使用雙圖案化的節點,這意味著他們必須將每個光刻步驟進行兩次;這既使每片晶圓的光刻設備利用率增加了一倍,同時也降低了產量。至少對于該節點來說,制造更小的晶體管所帶來的收益超過了成本。然而一年后,臺積電推出了 16nm 節點。這正是 3nm 所發生的情況——EUV 的收益現在明顯超過成本——而有關 2nm 密度和價格點的早期傳言表明,另一個節點的收益應該會持續下去。
芯片禁令
考慮到華盛頓特區對華為最近推出的配備 7nm 芯片的智能手機感到焦慮,這似乎是對出口管制的蔑視。
簡而言之,芯片禁令的問題在于在 10nm 上劃定界限:這條界限是任意的,因為制造 10 nm 芯片所需的設備已經被證明能夠生產 7 nm 芯片。
真正重要的是 5nm,換句話說,真正限制中國大陸長期發展的出口管制是 EUV。前些年,特朗普政府已經說服荷蘭不允許出口 EUV 設備,拜登政府通過芯片禁令以及與荷蘭的進一步協調進一步鎖定了 EUV 的出口。現實情況是,很多芯片制造設備都是「多節點」的;許多機器可以在多個節點上使用,但您必須擁有 EUV 設備才能延續摩爾定律,因為它是驅動摩爾定律的關鍵技術。
H800 是臺積電第三代 5nm 工藝(容易混淆的 N4)制造的,也就是說它是用 EUV 制造的;通信速度限制是有意義的,并且會使人工智能開發速度更慢、成本更高。
這引出了進一步的觀點:芯片禁令的回報不會立即顯現。整個想法有意義的唯一方法是摩爾定律是否繼續存在,因為這意味著五年或十年后可用的芯片將比現在存在的芯片更快、更便宜,從而擴大差距。同時,這個想法也取決于認真對待黃的論點,因為人工智能不僅需要力量,還需要規模。幸運的是,兩條戰線的進展都朝著正確的方向發展。
反對芯片禁令也存在很好的論據,包括一個明顯的事實,即中國大陸受到強烈激勵從頭開始建立替代品。也許在 20 年內,美國不僅會失去最有力的杠桿點,而且還將看到其最前沿的公司被中國的競爭削弱。

評論