理解神經網絡中的Dropout

dropout是指在深度學習網絡的訓練過程中,對于神經網絡單元,按照一定的概率將其暫時從網絡中丟棄。注意是暫時,對于隨機梯度下降來說,由于是隨機丟棄,故而每一個mini-batch都在訓練不同的網絡。
本文引用地址:http://www.czjhyjcfj.com/article/201807/383602.htm過擬合是深度神經網(DNN)中的一個常見問題:模型只學會在訓練集上分類,這些年提出的許多過擬合問題的解決方案,其中dropout具有簡單性而且效果也非常良好。
算法概述
我們知道如果要訓練一個大型的網絡,而訓練數據很少的話,那么很容易引起過擬合,一般情況我們會想到用正則化、或者減小網絡規模。然而Hinton在2012年文獻:《Improving neural networks by preventing co-adaptation of feature detectors》提出了,在每次訓練的時候,隨機讓一半的特征檢測器停過工作,這樣可以提高網絡的泛化能力,Hinton又把它稱之為dropout。
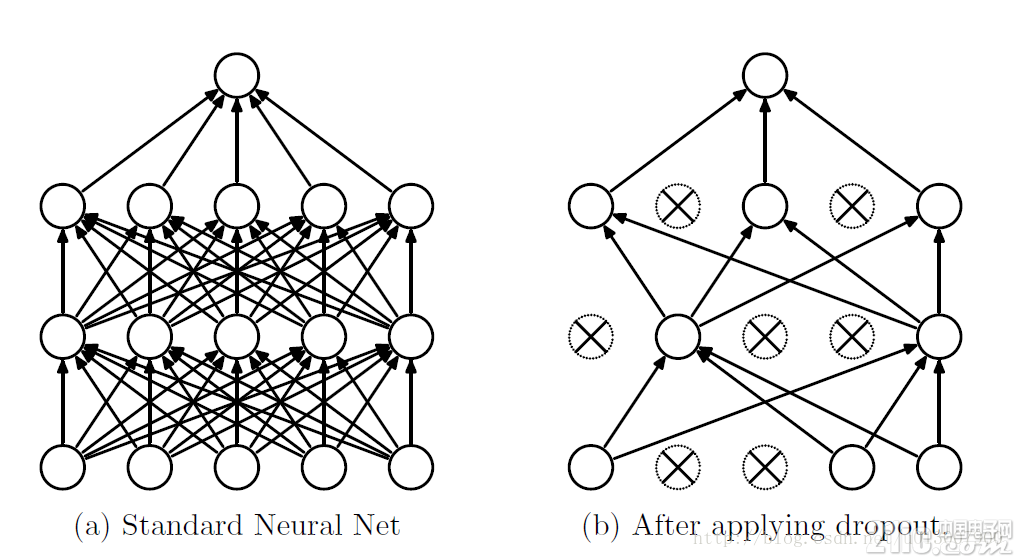
第一種理解方式是,在每次訓練的時候使用dropout,每個神經元有百分之50的概率被移除,這樣可以使得一個神經元的訓練不依賴于另外一個神經元,同樣也就使得特征之間的協同作用被減弱。Hinton認為,過擬合可以通過阻止某些特征的協同作用來緩解。
第二種理解方式是,我們可以把dropout當做一種多模型效果平均的方式。對于減少測試集中的錯誤,我們可以將多個不同神經網絡的預測結果取平均,而因為dropout的隨機性,我們每次dropout后,網絡模型都可以看成是一個不同結構的神經網絡,而此時要訓練的參數數目卻是不變的,這就解脫了訓練多個獨立的不同神經網絡的時耗問題。在測試輸出的時候,將輸出權重除以二,從而達到類似平均的效果。
需要注意的是如果采用dropout,訓練時間大大延長,但是對測試階段沒影響。
帶dropout的訓練過程
而為了達到ensemble的特性,有了dropout后,神經網絡的訓練和預測就會發生一些變化。在這里使用的是dropout以p的概率舍棄神經元
訓練層面
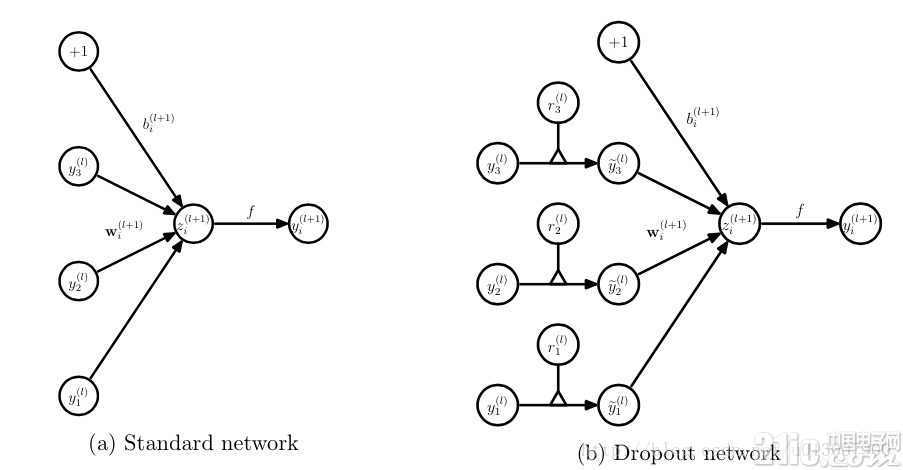
對應的公式變化如下如下:
沒有dropout的神經網絡
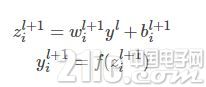
有dropout的神經網絡

無可避免的,訓練網絡的每個單元要添加一道概率流程。
測試層面
預測的時候,每一個單元的參數要預乘以p。
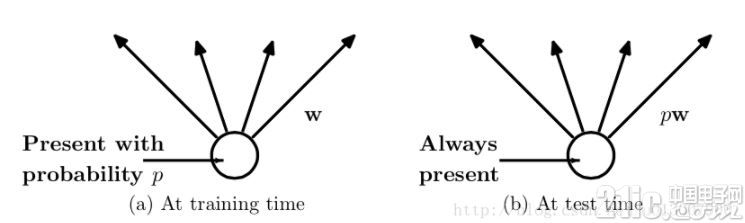
除此之外還有一種方式是,在預測階段不變,而訓練階段改變。

關于這個比例我查了不少資料,前面的是論文的結論;后面是keras源碼中dropout的實現。有博客寫的公式不一致,我寫了一個我覺得是對的版本。
Dropout與其它正則化
Dropout通常使用L2歸一化以及其他參數約束技術。正則化有助于保持較小的模型參數值。
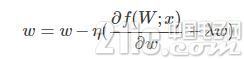
使用Inverted Dropout后,上述等式變為:
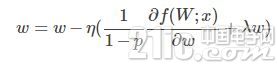
可以看出使用Inverted Dropout,學習率是由因子q=1−p進行縮放 。由于q在[0,1]之間,η和q之間的比例變化:
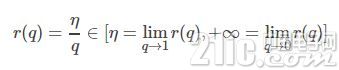
參考文獻將q稱為推動因素,因為其能增強學習速率,將r(q)稱為有效的學習速率。
有效學習速率相對于所選的學習速率而言更高:基于此約束參數值的規一化可以幫助簡化學習速率選擇過程。





評論