如何使用FPGA加速機器學習算法

當前,AI因為其CNN(卷積神經網絡)算法出色的表現在圖像識別領域占有舉足輕重的地位。基本的CNN算法需要大量的計算和數據重用,非常適合使用FPGA來實現。上個月,Ralph Wittig(Xilinx CTO Office的卓越工程師)在2016年OpenPower峰會上發表了約20分鐘時長的演講并討論了包括清華大學在內的中國各大學研究CNN的一些成果。
本文引用地址:http://www.czjhyjcfj.com/article/201710/366437.htm在這項研究中出現了一些和CNN算法實現能耗相關的幾個有趣的結論:
①限定使用片上Memory;
②使用更小的乘法器;
③進行定點匹配:相對于32位定點或浮點計算,將定點計算結果精度降為16位。如果使用動態量化,8位計算同樣能夠產生很好的結果。
在演講中Wittig還提到了CNN相關的兩款產品:CAPI-compatible Alpha DataADM-PCIE-8K5 PCIe加速卡和Auviz Systems提供的AuvizDNN(深度神經網絡)開發庫。
ADM-PCIE-8K5 PCIe加速卡
Alpha DataADM-PCIE-8K5 PCIe加速卡用于X86和IBM Power8/9數據中心和云服務,加速卡基于Xilinx Kintex UltraScale KU115 FPGA,支持Xilinx SDAcess基于OpenCL、C/C++的開發和基于Vivado HLx的HDL、HLS設計流程。

圖1 Alpha DataADM-PCIE-8K5 PCIe加速卡
Alpha DataADM-PCIE-8K5 PCIe加速卡片上帶32GB DDR4-2400內存(其中16GB含ECC),雙通道SFP+支持雙通道10G以太網接入。提供包括高性能PCIe/DMA在內的板級支持包(BSP) 、OpenPOWER架構的CAPI、FPGA參考設計、即插即用的O/S驅動和成熟的API等設計資源。
AuvizDNN開發庫
深度學習技術使用大量的已知數據來找出一組權重和偏置值來匹配預期結果。處理被稱之為訓練,訓練的結果是大量的模型,這一事實促使工程師們尋求使用GPU之類的專用硬件來進行訓練和分類計算。
隨著未來數據量的巨幅增長,機器學習將會搬到云端完成。這樣就急需一種既可以加速算法,又不會大規模增加功耗的處理平臺,在這種情況下,FPGA開始登場。
隨著一些列的先進開發環境投入使用,軟件開發工程師將他們的設計在Xilinx FPGA上實現變得更加容易。Auviz Systems開發的AuvizDNN庫為用戶提供優化的函數接口,用戶可以針對不同的應用創建自定義的CNN。這些函數可以方便的通過Xilinx SDAcess這樣的集成開發環境調用。在創建對象和數據池后,就會調用函數創建每一個卷積層、然后是致密層,最后是 softmax層,如下圖2所示。
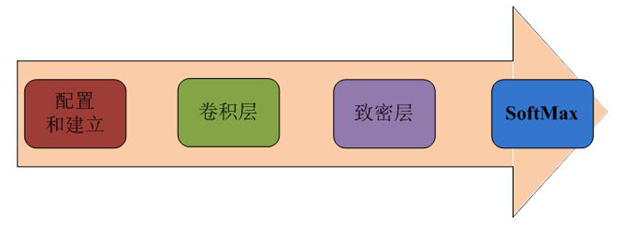
圖2 實現CNN的函數調用順序













評論