浮點矩陣相乘IP核并行改進的設計與實現

嵌入式計算作為新一代計算系統的高效運行方式,應用于多個高性能領域,如陣列信號處理、核武器模擬、計算流體動力學等。在這些科學計算中,需要大量的浮點矩陣運算。而目前已實現的浮點矩陣運算是直接使用VHDL語言編寫的浮點矩陣相乘處理單元[1],其關鍵技術是乘累加單元的設計,這樣設計的硬件,其性能依賴于設計者的編程水平。此外,FPGA廠商也推出了一定規模的浮點矩陣運算IP核[2],雖然此IP核應用了本廠家的器件,并經過專業調試和硬件實測,性能穩定且優于手寫代碼,但仍可對其進行改進,以進一步提高運算速度。
1 Altera浮點矩陣相乘IP核原理
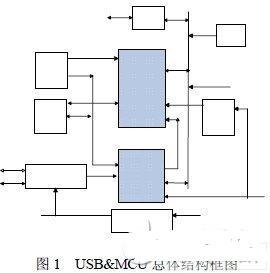
Altera公司推出的浮點矩陣相乘IP核ALTFP_MATRIX_MULT,是在Quartus軟件9.1版本以上的環境中使用,能夠進行一定規模的浮點矩陣相乘運算,包含A、B矩陣數據輸入,數據浮點乘加,數據緩存及相加輸出四大部分。其中最能體現浮點計算性能的是浮點乘加部分,而周圍的控制電路及輸出則影響到系統的最高時鐘頻率,間接地影響系統整體性能。
整個矩陣相乘電路原理是將輸入的單路數據(A、B矩陣共用數據線),通過控制器產生A、B矩陣地址信號,控制著A矩陣數據輸出和B矩陣數據輸出,并將數據并行分段輸出到浮點乘加模塊進行乘加運算,之后串行輸出到一個緩存器模塊中,再以并行方式輸出到浮點相加模塊,最后獲得計算結果。從其原理可以看出,在數據輸入輸出方面仍有許多可改進的地方。
2 IP核存在的缺陷及改進
2.1 存在缺陷
(1)輸入數據帶寬的不均衡性。在矩陣A、B的數據輸入時,Altera的IP核將A矩陣數據存于M144K的Block RAM中,而將B矩陣數據存于M9K的Block RAM中,導致IP核中A矩陣數據的帶寬小于B矩陣數據的帶寬,并需要一定數量的寄存器組使A矩陣數據帶寬能夠匹配于B矩陣數據帶寬。由此可見,A、B矩陣數據的存儲受到器件限制和存儲約束,同時由于在浮點乘加模塊的輸入端(A、B矩陣數據)帶寬不同,造成A矩陣數據的輸入需要額外的處理時間。
(2)加載數據的不連貫性。在矩陣數據加載時,IP核通過將數據分段成等分的幾部分,用于向量相乘。由于矩陣A存儲帶寬窄需要4步寄存(由Blocks決定),在第3個周期時才加載數據B用于計算,送到一個FIFO中存儲;在第6個時鐘周期時加載矩陣A分段的第二部分進行各自的第二部分計算,最后當計算到第15個周期時,才可通過浮點相加,計算出矩陣C的第一個值,之后計算出矩陣C的其他值C11。從上述結構可見,在分段相乘之后,采用先對一個FIFO進行存儲,存滿后再對下一個數據FIFO進行存儲,造成時間上浪費過多。
2.2 設計改進
鑒于上述缺陷,在輸入A、B矩陣的存儲方式上,進行串行輸入到并行輸入的改進,使得兩個矩陣能同步輸入到浮點乘加模塊。在數據加載方式上,將A矩陣用3個周期加載完畢,再處理相乘運算;將分段相乘結果進行直接存儲相加,獲得C矩陣的第一個值,縮減運算時間。設計的改進框圖如圖1所示。
浮點矩陣相乘IP核并行改進的設計與實現.pdf

評論