基于黑板的多Agent智能決策支持系統(tǒng)的Agent實現(xiàn)

Agent是人工智能和對象實體相結合的產物,是能夠獨立、自動代替用戶執(zhí)行某一特定任務的程序。Agent所具有的自治、協(xié)作、學習、歸納、推理等特性能夠支持各階段的決策制定和問題求解,增強傳統(tǒng)決策支持系統(tǒng)的功能。基于Agent的結構提供可柔性、可變性、魯棒性,適用于解決一些動態(tài)的,不確定的和分布式的問題。Agent之間通過相互調度、合作協(xié)同完成大規(guī)模的復雜問題求解。由于絕大多數(shù)工作都是在特定的群體環(huán)境中由組成群體的各主體分工協(xié)作、共同完成的。大多數(shù)工作同時伴隨著決策過程,而決策過程的優(yōu)劣直接影響工作任務的順利完成,因此,Agent技術使建立一個網絡化、智能化、集成化的人機協(xié)調的智能決策支持系統(tǒng)成為現(xiàn)實。
在傳統(tǒng)的智能決策支持系統(tǒng)的基礎上,提出了一種基于黑板的多Agent智能決策支持系統(tǒng)。在該系統(tǒng)中,黑板能為分布式結構系統(tǒng)提供公共工作區(qū),每個Agent可利用黑板充分交換信息、數(shù)據(jù)和知識,任意時候訪問黑板,查詢發(fā)布內容,然后各自提取所需的工作信息,以便完成各自擔當?shù)娜蝿眨⑶彝ㄟ^黑板協(xié)調各個Agent,使多個Agent共同協(xié)作來求解給定的問題,同時強調將決策者的智慧和系統(tǒng)相結合。
2 基于黑板的多Agent智能決策支持系統(tǒng)
在基于黑板的多Agent智能決策支持系統(tǒng)中,每種決策任務或功能是由獨立的Agent完成,各種Agent通過相應標準從各自角度分析問題,每個Agent能力、意志和信念的不同,使它們具有問題求解領域的知識以及問題求解的技能也不同。不同的Agent從自身角度審視決策問題獨立完成子任務,然后通過黑板協(xié)同合作實現(xiàn)共同目標。由于Agent的自治性和實體化,可以隨時加入或離開一個問題求解系統(tǒng),使得決策者方便地參與到決策過程中,從而保證系統(tǒng)的靈活性。這里所構建的系統(tǒng)結構為交互層、智能決策層和資源層的3層體系結構,如圖1所示。其中智能界面Agent和決策用戶組成交互層;黑板、功能Agent和決策Agent組成智能決策層;模型庫及模型庫管理系統(tǒng)、知識庫及知識庫管理系統(tǒng)、方法庫及方法庫管理系統(tǒng)及數(shù)據(jù)倉庫和多庫協(xié)同器組成資源層。
2.1 智能界面Agent
智能界面Agent是基于Agent的智能決策支持系統(tǒng)體系結構中與決策者聯(lián)系的部件,能夠獨立持續(xù)運行。系統(tǒng)通過它和決策者通信,或利用學習用戶的目標、愛好、習慣、經驗、行為等,使用戶高效地完成任務。智能界面A―gent代替?zhèn)鹘y(tǒng)的人機交互界面,強調Agent的自主性和學習性,可以主動探測環(huán)境變化,在與用戶交互共同作用的決策中,通過不斷學習,獲得用戶某些特征知識,從而在決策過程中根據(jù)感知到的用戶行為方式提供合適的用戶界面,自主地做出與用戶意志相符合的策略。智能界面Agent的全局知識中主要包括:問題領域知識、用戶模型或用戶知識、自身知識、其他Agent能力知識。它采用發(fā)現(xiàn)和模擬用戶學習知識,獲得用戶的正向和反向反饋學習知識.用戶的指導獲得知識,通過與其他Agent的通訊獲取知識等。
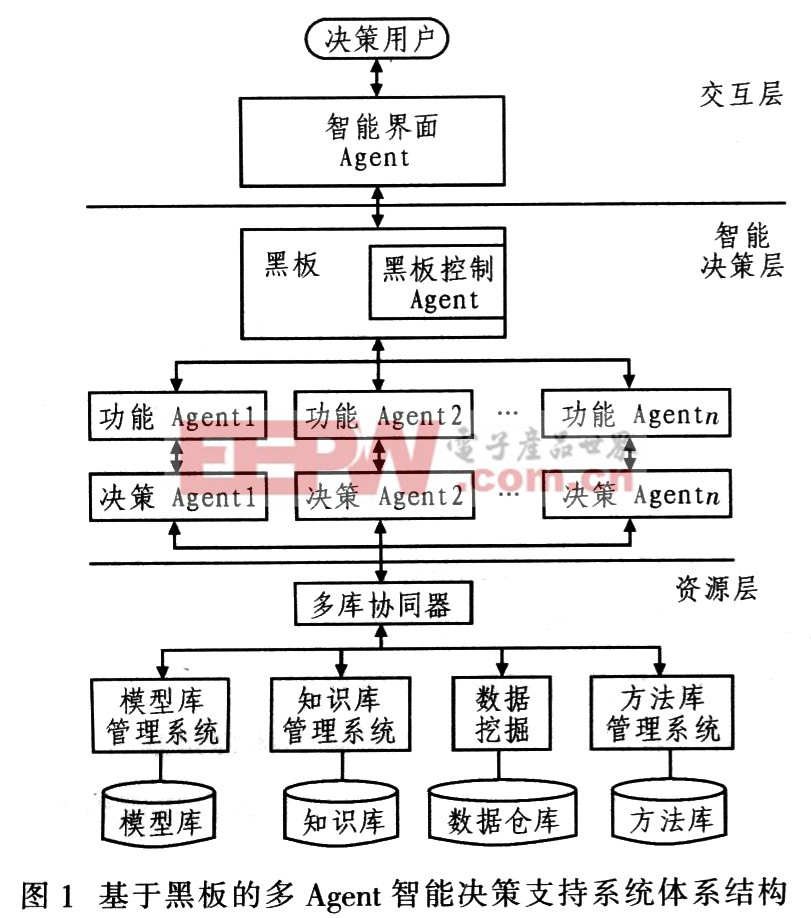
2.2 功能Agent
功能Agent監(jiān)督黑板數(shù)據(jù)平面變化,匹配各決策A―gent的激活條件和黑板各平面信息,將黑板上的信息發(fā)給相應的決策Agent。功能Agent利用系統(tǒng)的消息、隊列機制發(fā)送黑板上的信息,并且負責報告系統(tǒng)運行情況,向用戶報告任務完成情況,并提供解釋和查詢。其內部有一個各決策Agent讀黑板的激活條件表,當黑板各層信息變化時,則檢查與該層信息變化有關的激活條件表,如果匹配,則進一步分析,決定是直接激活相應的決策Agent讀取黑板信息完成相應的任務或者是做其他操作,例如提供報告和解釋等。同時還隨時提供系統(tǒng)執(zhí)行情況的查詢。它實際上就是一個可以對黑板上信息、變化進行感知的反應型Agent,每當黑板上信息改變時觸發(fā)它的檢查黑板各數(shù)據(jù)平面動作。
2.3 決策Agent
決策Agent在某個特定領域有解決問題的知識和技能。把每一種決策方法設計為一個決策Agent,多個決策Agent在功能Agent的控制和監(jiān)督下,通過相互間的協(xié)調和合作,能夠解決復雜決策問題。這類Agent是可擴展的,隨著決策理論的發(fā)展和智能化決策方法的進步,可以開發(fā)更多的決策Agent。決策Agent沒有關于外部環(huán)境的模型,沒有關于其他Agent的知識,但仍然有與其他Agent交互的能力。
3 Agent的實現(xiàn)技術
3.1 Agent的抽象結構
Agent行為包含:感知、認知、行為3個階段。首先感知外部環(huán)境信息,然后由認知處理部分根據(jù)自身狀態(tài),通過制定相應的決策方案,根據(jù)決策方案從多種決策方法中選擇并執(zhí)行合適的方法,從而表現(xiàn)出主動的智能行為。在認知處理中,還需要進行規(guī)劃及學習等過程,從而不斷學習新的知識,使Agent智能不斷提高。行為輸出部分通過Agent行為對外界環(huán)境施加影響。以下對Agent進行形式的抽象描述:
首先假設環(huán)境是任何離散的瞬時狀態(tài)的有限集合E:E={e,e’…},Agent有一個可執(zhí)行動作的清單,可改變環(huán)境狀態(tài)Ac={a,a’…}為(有限的)動作集合。
環(huán)境從某個狀態(tài)開始,Agent選擇一個動作作用于該狀態(tài)。動作結果是環(huán)境可能到達的某些狀態(tài)。然而,只有一個狀態(tài)可以真正實現(xiàn),當然,Agent事先并不知道哪個狀態(tài)會實現(xiàn)。在第二個狀態(tài)的基礎上,Agent繼續(xù)選擇一個動作執(zhí)行,環(huán)境到達可能狀態(tài)集中的一個狀態(tài)。然后,Agent再選擇另一個動作,如此繼續(xù)下去。
Agent在環(huán)境中一次執(zhí)行r是環(huán)境狀態(tài)e與動作a交替的一個序列。假設:R是所有可能的(和上的)有限序列集合:RAC是以動作結束的序列所組成的R子集;RE是以狀態(tài)結束的序列所組成的R子集;用r,r’…代表R的成員。
為了表示Agent的動作作用于環(huán)境的效果,引入狀態(tài)轉移函數(shù)τ:RAC→RE。狀態(tài)轉移函數(shù)建立一個執(zhí)行(假設以Agent的動作作為結束)與可能的環(huán)境狀態(tài)集合之間的映射,這些環(huán)境狀態(tài)是動作執(zhí)行的結果。


評論