如何使用PyTorch訓(xùn)練LLM

推薦:使用NSDT場景編輯器快速搭建3D應(yīng)用場景
像LangChain這樣的庫促進了上述端到端AI應(yīng)用程序的實現(xiàn)。我們的教程介紹 LangChain for Data Engineering & Data Applications 概述了您可以使用 Langchain 做什么,包括 LangChain 解決的問題,以及數(shù)據(jù)用例的示例。
本文將解釋訓(xùn)練大型語言模型的所有過程,從設(shè)置工作區(qū)到使用 Pytorch 2.0.1 的最終實現(xiàn),Pytorch <>.<>.<> 是一個動態(tài)且靈活的深度學(xué)習(xí)框架,允許簡單明了的模型實現(xiàn)。
先決條件
為了充分利用這些內(nèi)容,重要的是要熟悉 Python 編程,對深度學(xué)習(xí)概念和轉(zhuǎn)換器有基本的了解,并熟悉 Pytorch 框架。完整的源代碼將在GitHub上提供。
在深入研究核心實現(xiàn)之前,我們需要安裝和導(dǎo)入相關(guān)庫。此外,重要的是要注意,訓(xùn)練腳本的靈感來自 Hugging Face 中的這個存儲庫。
庫安裝
安裝過程詳述如下:
首先,我們使用語句在單個單元格中運行安裝命令作為 Jupyter 筆記本中的 bash 命令。%%bash
Trl:用于通過強化學(xué)習(xí)訓(xùn)練轉(zhuǎn)換器語言模型。
Peft使用參數(shù)高效微調(diào)(PEFT)方法來有效地適應(yīng)預(yù)訓(xùn)練的模型。
Torch:一個廣泛使用的開源機器學(xué)習(xí)庫。
數(shù)據(jù)集:用于幫助下載和加載許多常見的機器學(xué)習(xí)數(shù)據(jù)集。
變形金剛:由Hugging Face開發(fā)的庫,帶有數(shù)千個預(yù)訓(xùn)練模型,用于各種基于文本的任務(wù),如分類,摘要和翻譯。
現(xiàn)在,可以按如下方式導(dǎo)入這些模塊:
數(shù)據(jù)加載和準備
羊駝數(shù)據(jù)集,在擁抱臉上免費提供,將用于此插圖。數(shù)據(jù)集有三個主要列:指令、輸入和輸出。這些列組合在一起以生成最終文本列。
加載數(shù)據(jù)集的指令在下面通過提供感興趣的數(shù)據(jù)集的名稱給出,即:tatsu-lab/alpaca

我們可以看到,結(jié)果數(shù)據(jù)位于包含兩個鍵的字典中:
特點:包含主列數(shù)據(jù)
Num_rows:對應(yīng)于數(shù)據(jù)中的總行數(shù)

train_dataset的結(jié)構(gòu)
可以使用以下說明顯示前五行。首先,將字典轉(zhuǎn)換為熊貓數(shù)據(jù)幀,然后顯示行。


train_dataset的前五行
為了獲得更好的可視化效果,讓我們打印有關(guān)前三行的信息,但在此之前,我們需要安裝庫以將每行的最大字數(shù)設(shè)置為 50。第一個 print 語句用 15 個短劃線分隔每個塊。textwrap


前三行的詳細信息
模型訓(xùn)練
在繼續(xù)訓(xùn)練模型之前,我們需要設(shè)置一些先決條件:
預(yù)訓(xùn)練模型:我們將使用預(yù)訓(xùn)練模型Salesforce/xgen-7b-8k-base,該模型可在Hugging Face上使用。Salesforce 訓(xùn)練了這一系列名為 XGen-7B 的 7B LLM,對高達 8K 的序列進行了標準的密集關(guān)注,最多可獲得 1.5T 代幣。
分詞器: 這是訓(xùn)練數(shù)據(jù)上的標記化任務(wù)所必需的。加載預(yù)訓(xùn)練模型和分詞器的代碼如下:
pretrained_model_name = "Salesforce/xgen-7b-8k-base"
model = AutoModelForCausalLM.from_pretrained(pretrained_model_name, torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name, trust_remote_code=True)
訓(xùn)練配置
訓(xùn)練需要一些訓(xùn)練參數(shù)和配置,下面定義了兩個重要的配置對象,一個是 TrainingArguments 的實例,一個是 LoraConfig 模型的實例,最后是 SFTTrainer 模型。
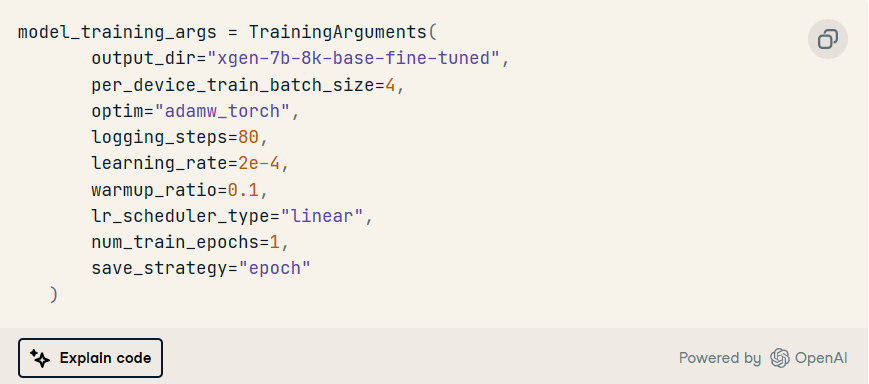
訓(xùn)練參數(shù)
這用于定義模型訓(xùn)練的參數(shù)。
在此特定場景中,我們首先使用屬性定義存儲訓(xùn)練模型的目標,然后再定義其他超參數(shù),例如優(yōu)化方法、優(yōu)化方法、、 等。output_dirlearning ratenumber of epochs
洛拉康菲格
用于此方案的主要參數(shù)是 LoRA 中低秩轉(zhuǎn)換矩陣的秩, 設(shè)置為 16.然后, LoRA 中其他參數(shù)的比例因子設(shè)置為 32.
此外,輟學(xué)比率為 0.05,這意味著在訓(xùn)練期間將忽略 5% 的輸入單元。最后,由于我們正在處理一個普通語言建模,因此該任務(wù)使用屬性進行初始化。CAUSAL_LM
SFTTrainer
這旨在使用訓(xùn)練數(shù)據(jù)、分詞器和附加信息(如上述模型)來訓(xùn)練模型。
由于我們使用訓(xùn)練數(shù)據(jù)中的文本字段,因此查看分布以幫助設(shè)置給定序列中的最大令牌數(shù)非常重要。
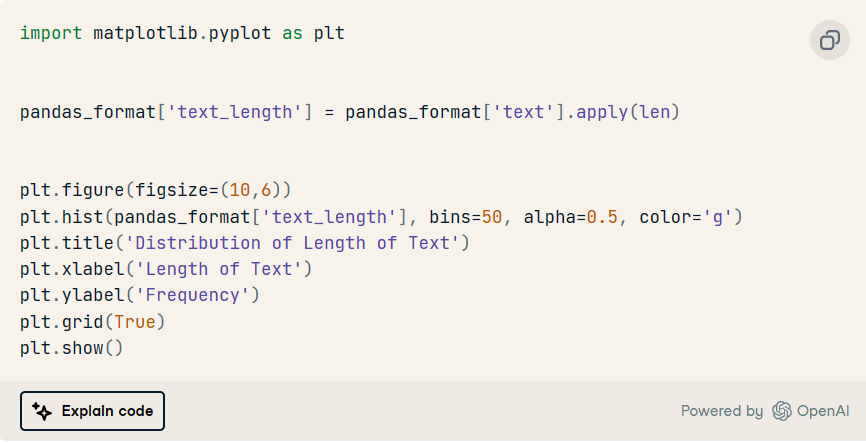
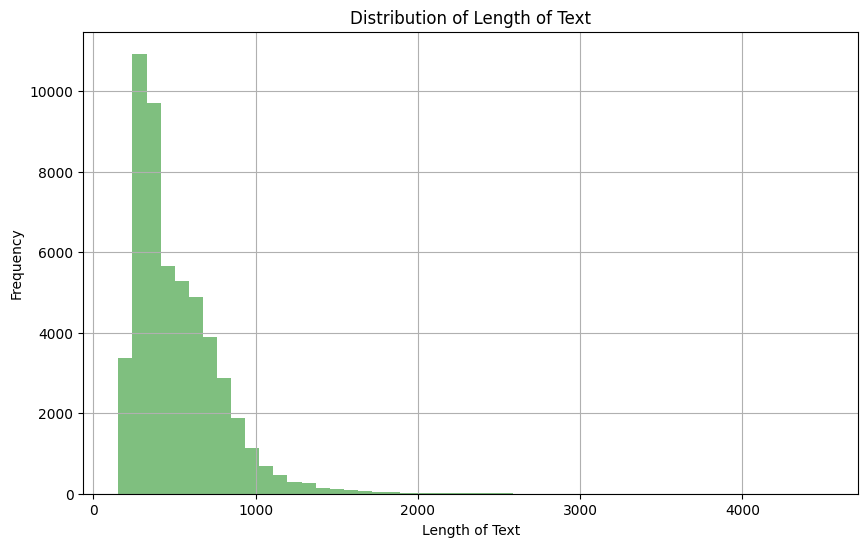
文本列長度的分布
基于上述觀察,我們可以看到大多數(shù)文本的長度在 0 到 1000 之間。此外,我們可以在下面看到,只有 4.5% 的文本文檔的長度大于 1024。
mask = pandas_format['text_length'] > 1024
percentage = (mask.sum() / pandas_format['text_length'].count()) * 100
print(f"The percentage of text documents with a length greater than 1024 is: {percentage}%")

然后,我們將序列中的最大標記數(shù)設(shè)置為 1024,以便任何比此長度的文本都被截斷。
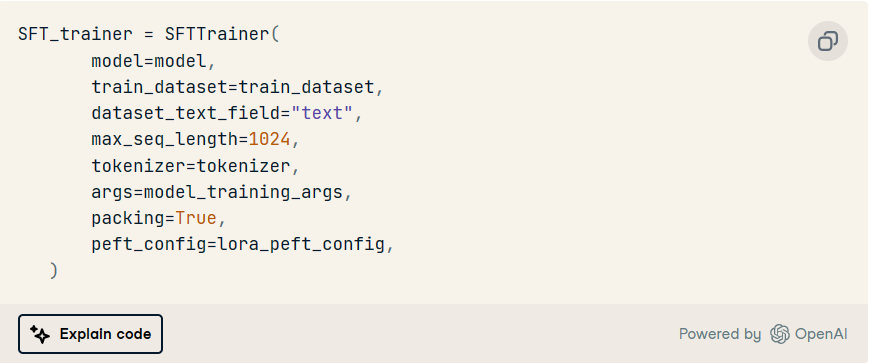
培訓(xùn)執(zhí)行
滿足所有先決條件后,我們現(xiàn)在可以按如下方式運行模型的訓(xùn)練過程:

值得一提的是,此培訓(xùn)是在具有GPU的云環(huán)境中進行的,這使得整個培訓(xùn)過程更快。但是,在本地計算機上進行培訓(xùn)需要更多時間才能完成。
我們的博客,在云中使用LLM與在本地運行LLM的優(yōu)缺點,提供了為LLM選擇最佳部署策略的關(guān)鍵考慮因素
讓我們了解上面的代碼片段中發(fā)生了什么:
tokenizer.pad_token = tokenizer.eos_token:將填充標記設(shè)置為與句尾標記相同。
model.resize_token_embeddings(len(tokenizer)):調(diào)整模型的標記嵌入層的大小,以匹配分詞器詞匯表的長度。
model = prepare_model_for_int8_training(model):準備模型以進行 INT8 精度的訓(xùn)練,可能執(zhí)行量化。
model = get_peft_model(model, lora_peft_config):根據(jù) PEFT 配置調(diào)整給定的模型。
training_args = model_training_args:將預(yù)定義的訓(xùn)練參數(shù)分配給training_args。
trainer = SFT_trainer:將 SFTTrainer 實例分配給變量訓(xùn)練器。
trainer.train():根據(jù)提供的規(guī)范觸發(fā)模型的訓(xùn)練過程。
結(jié)論
本文提供了使用 PyTorch 訓(xùn)練大型語言模型的明確指南。從數(shù)據(jù)集準備開始,它演練了準備先決條件、設(shè)置訓(xùn)練器以及最后運行訓(xùn)練過程的步驟。
盡管它使用了特定的數(shù)據(jù)集和預(yù)先訓(xùn)練的模型,但對于任何其他兼容選項,該過程應(yīng)該大致相同。現(xiàn)在您已經(jīng)了解如何訓(xùn)練LLM,您可以利用這些知識為各種NLP任務(wù)訓(xùn)練其他復(fù)雜的模型。
原文鏈接:如何使用PyTorch訓(xùn)練LLM (mvrlink.com)
*博客內(nèi)容為網(wǎng)友個人發(fā)布,僅代表博主個人觀點,如有侵權(quán)請聯(lián)系工作人員刪除。
