應(yīng)用兩級分類實(shí)現(xiàn)車牌字符識別


當(dāng)CF(B)的值大于形近字判別閾值CFmin時,直接輸出粗分類識別結(jié)果;反之,分類器查找形近字所屬類別,并將字符送入二級分類識別。
2.4 粗分類實(shí)驗(yàn)和分析
粗分類中字母和數(shù)字共有33類,每類有100個樣本。其中每類用60個樣本進(jìn)行SVM訓(xùn)練,構(gòu)造SVM分類器,剩下的40個樣本做測試。
本文對粗分類器在不同可信度閾值下的性能進(jìn)行了測試,測試結(jié)果如圖4所示。從圖中可以看出,粗分類識別率隨著可信度閾值的增加而提高,但閾值設(shè)置太高時,粗分類有較高的拒識率,而將字符送入二級分類識別,導(dǎo)致浪費(fèi)粗分類器的識別能力。所以可信度閾值選取0.7,粗分類器的識別性能最佳。
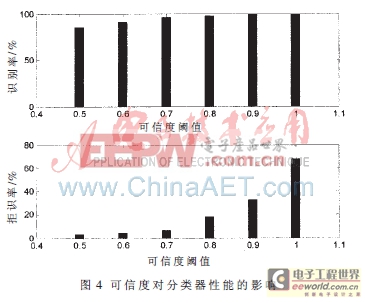
當(dāng)CFmin=0.7時,粗分類字符識別正確率只有96.4%,但是出現(xiàn)錯誤的字符基本上都是形近字。如8、B、O、D、Q,2、Z,5、S等外形比較相似的字符,這些形近字符的差別體現(xiàn)在細(xì)微的結(jié)構(gòu)上。如果將這些形近字符暫時歸為一類,然后將其送入二級分類識別,則粗分類識別正確率會大幅提升接近100%,這樣的結(jié)果可以滿足特征提取算法復(fù)雜度低,識別率較高、形近字較少的粗分類的要求。
3 二級分類識別
3.1 細(xì)分類特征提取
細(xì)分類的特征提取方法應(yīng)該能夠表征字符細(xì)節(jié)信息,刻畫形近字間更細(xì)微的差別。結(jié)構(gòu)特征可以很好地反映字符的細(xì)節(jié)特征。所以本文選取環(huán)數(shù)、彎曲度、交點(diǎn)數(shù)等結(jié)構(gòu)特征作為細(xì)分類的特征提取方法。
(1)環(huán)數(shù)(H):字符中閉合曲線的個數(shù)。
(2)彎曲度(R):設(shè)字符中光滑曲線段的兩個端點(diǎn)為M(Mx,My)和N(Nx,Ny),這兩點(diǎn)所構(gòu)成線段為MN,曲線到線段MN垂直距離最遠(yuǎn)的點(diǎn)為T,對應(yīng)的投影點(diǎn)為P,點(diǎn)T到線段MN的距離Dtp和該線段長度Dmn的比值為彎曲度R,則: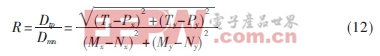
(3)交點(diǎn)數(shù)(E):在水平或垂直方向上掃描字符時與字符相交的次數(shù)。以左右上下水平垂直的首字母L、R、T、B、L、V與特征的組合表示具體提取的特征,如TR表示上筆畫彎曲度。
在二級分類識別中,分類器根據(jù)環(huán)數(shù)、彎曲度和交點(diǎn)數(shù)等結(jié)構(gòu)特征的邏輯組合對形近字進(jìn)行分類識別,得出的決策表如表1所示。例如,字符‘2’和‘Z’的差別在于上面橫筆畫的彎曲度;字符‘C’和‘G’的差別在于垂直交點(diǎn)數(shù)。
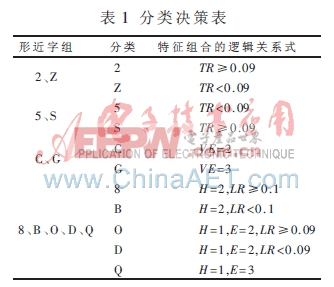
3.2細(xì)分類實(shí)驗(yàn)和分析
形近字符分為四組,每組選120個樣本做測試,形近字符的識別結(jié)果如表2所示。

表2中形近字符是否具有較高的識別率,在很大程度上取決于特征的選取。首先將形近字符分成不同的組,然后根據(jù)細(xì)微的差別提取不同的結(jié)構(gòu)特征,使得同一組中不同字符之間的細(xì)微差異能比較穩(wěn)定地體現(xiàn)出來,這是正確識別形近字的關(guān)鍵。實(shí)驗(yàn)表明決策表可以很好地區(qū)分形近字符,達(dá)到二級細(xì)分類識別的要求。
4 實(shí)驗(yàn)結(jié)果
實(shí)驗(yàn)中的測試車牌圖像是由重慶易博數(shù)字有限公司研制的電子警察在高速公路收費(fèi)站拍攝的,總共采集了一天中不同時段的幾千幅車牌圖像,大部分為本市的車輛,所以車牌圖像中的漢字均相同。在測試時,從這幾千幅車牌圖像中,總共選取1 200幅車牌圖像,并隨機(jī)分為3組作為實(shí)驗(yàn)中的測試車牌圖像,且僅統(tǒng)計(jì)英文字母和數(shù)字部分的識別率,最終的識別率以車牌牌照為單位進(jìn)行實(shí)驗(yàn),識別結(jié)果如表3所示。

本文算法在P4 2.80 GB、512 MB計(jì)算機(jī)上,用VC6. 0編程實(shí)現(xiàn),平均識別一個車牌需要0.3 s左右的時間。
本文在分析常用的車牌識別方法和人眼視覺活動特點(diǎn)的基礎(chǔ)上,設(shè)計(jì)了一種由粗到細(xì)的二級識別算法,使車牌中易混的形近字符識別率得以提高。在特征提取方面將統(tǒng)計(jì)特征和結(jié)構(gòu)特征相結(jié)合,并對提取的輪廓特征進(jìn)行優(yōu)化,使其有效地克服了字符偏移的影響。引入可信度評判機(jī)制,提升了分類識別的靈活性和可靠性。從實(shí)驗(yàn)結(jié)果可以看出,本文的算法取得了較高的識別正確率,實(shí)時性好,可以滿足實(shí)際應(yīng)用的需要。
參考文獻(xiàn)
[1] 高勇.車牌識別系統(tǒng)中的字符分割與識別[D].合肥:安徽大學(xué),2007.
[2] HUANG R, TAWFIK H, NAGAR A K. License plate character recognition based on support vector machines with colonel Selection and Fish Swarm Algorithms[C]. International Conference on Computer Modeling and Simulation, 2009:101-106.
[3] 李琳,張曉龍. 基于RBF核的SVM學(xué)習(xí)算法的優(yōu)化計(jì)算[J].計(jì)算機(jī)工程與應(yīng)用,2006,29:190-192.

評論