利用高效的編程技術發揮多內核架構優勢

TI的OMAP 44xx平臺整合了ARM Cortex-A9、PowerVR SGX 540 GPU、C64x DSP和圖像信號處理器。每個內核有專門的功能,處理器之間的通信不是對稱的。OMAP只工作在AMP模式,而P4080的內核是SMP系統,但也能夠將內核劃分為AMP模式。8內核芯片可以像8個獨立內核那樣運行,在許多配置中也可以聯合起來使用(如一對雙內核SMP子系統,或四個單內核子系統)。
OMAP和P4080在高層架構的主要區別是OMAP功能是固定的,內核針對各自的事務做了優化。這將使編程容易得多,因為可以根據匹配功能將應用程序劃分到特定內核。
每個子系統的性能水平受架構的限制,但P4080可以調整劃分方案,雖然劃分通常是在系統啟動時完成的。系統設計師可以調整P4080中內核的分配,前提是有足夠多的內核。市場上也有內核數量較少的QorIQ平臺,因此可以選用更經濟的芯片。
IBM的Cell處理器填補了中間的空白。它采用了1個64位的Power內核和8個增效處理單元(SPE)。所有SPE都是相同的(每個有256KB的內存),它們工作在隔離狀態,這與上述討論的共享內存SMP系統有所不同。SPE內沒有緩存,也不支持虛擬內存。
對軟硬件設計來說,這種方式既有優點又有缺點。優點為是簡化了硬件實現,但從多個角度看都使軟件復雜化了。例如,內存管理受應用程序控制,就像內核間的通信一樣。數據在能夠操作之前必須要移進SPE的本地內存。完全開發Cell這樣的架構很花時間,因為它們有別于更傳統的SMP或AMP平臺。多年來在像索尼的PlayStation 3這樣的基于Cell的平臺上所作的軟件改進突顯了編程技術和經驗的變化。
GPU等專用處理器
改變編程技術是使用圖形處理單元(GPU)是否成功的關健。來自ATI和Nvidia等公司的GPU在單個芯片內有上百個內核,這些GPU可以被整合進多芯片解決方案,向開發人員提供上千個內核。例如,集成進1U機箱的4個Nvidia Tesla T10就可以提供960個內核(圖4)。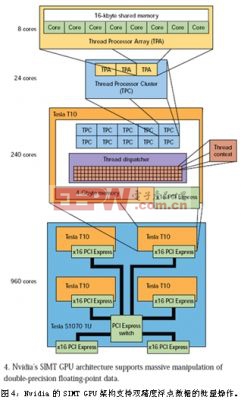
對Tesla或其它任何兼容的Nvidia GPU芯片進行編程都極具挑戰性,但類似Nvidia的CUDA這樣的架構或基于CUDA的運行時利用可以使工作變得更加輕松。部分挑戰來自于Nvidia GPU的單指令、多線程(SIMT)架構。與許多高性能系統一樣,這種GPU喜歡處理數組數據。對許多應用來說這是不錯的選擇,但并非都是這樣,這正是GPU經常要與多內核CPU匹配的原因之一。
另一種并行編程架構,CUDA和OpenCL(開放計算語言),則完全匹配GPU方法(使用與主處理器分開的存儲器)。這意味著數據在能被操作之前必須從一個地方移動到另一個地方。C編程語言有一定擴展,但也有限制。例如,它是自由遞歸的,不支持函數指針。其中一些限制源自SIMT方法。
許多應用程序使用CUDA,但與傳統SMP平臺相比,性能增益有很大的變化,從2倍到100倍不等。造成這種變化的原因是,線程以32為組運行時的效率最高。分支不影響性能,前提是32線程組在同一分支內。
像GPU這樣的專用處理器,其采用的方案是同時提供圖形和多內核處理。另外一種方案是使用許多傳統內核,如Intel的Larrabee(圖5)。Larrabee使用專門針對矢量處理優化過的x86兼容內核。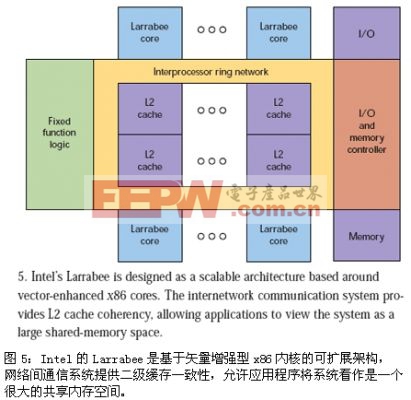

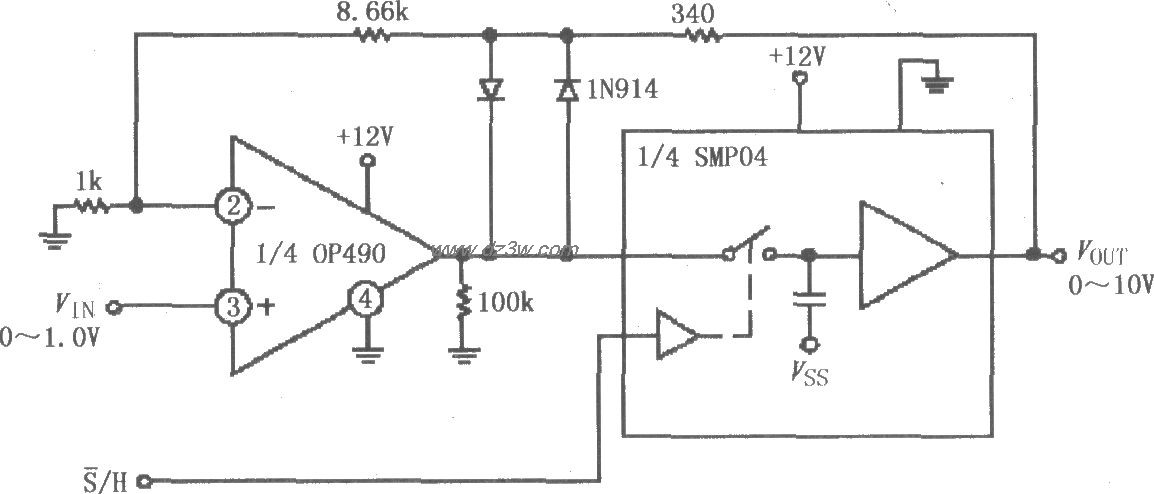






評論