孤立詞語音識別系統的DSP實現

為了比較它們的相似度,可以計算,它們之間的失真D[T,R],失真越小相似度越高。為了計算這一失真,應從T和R中各個對應幀之間的失真算起。將各個對應幀之間的失真累計起來就可以得到兩模式間的總失真。很容易想到的辦法是當兩模式長度相等時,直接以相等的幀號相匹配后累加計算總失真,而當兩個模式長度不等時則利用線性擴張或線性壓縮的方法使兩模式具有相等長度,隨后進行匹配計算失真度。但由于人類發音具有隨機的非線性變化,這種方法效果不可能是最佳的。為了達到最佳效果,可以采用動態時間規整的方法。如圖4所示,橫坐標對應“1”這個字音的一次較短的發音,經過分幀和特征矢量計算后共得到一個長度為43幀的語音序列,而縱坐標對應“1”這個字音的一次較長的發音,該語音特征序列共有56幀。為了找到兩個序列的最佳匹配路徑,現把測試模式的各個幀號n=1~N(圖4中N=43)在一個二維直角坐標系中的橫軸上標出,把參考模式的各幀號m=1~M(圖4中M=56)在縱軸上標出。本文引用地址:http://www.czjhyjcfj.com/article/152294.htm
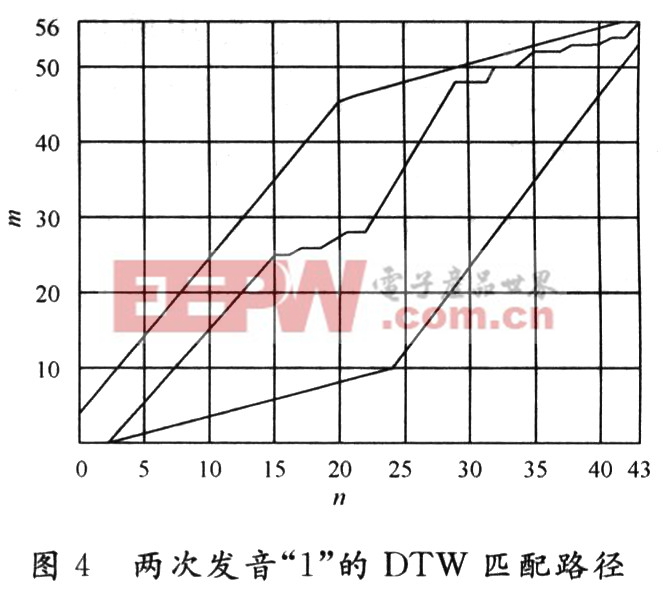
通過這些表示幀號的整數坐標畫一些縱橫線即可形成一個網格,網格中何一個節點(n,m)表示測試模式中的某一幀和參考模式中的某一幀的交匯點。動態時間規整算法可以歸結為尋找一條通過此網格中若干交叉點的路徑,路徑通過的交叉點即為參考模式和測試模式中進行失真計算的幀號。路徑不是隨意選擇的,首先任何一種語音的發音快慢可能有變化,但是各部分的先后順序不可能改變,因此所選的路徑必定從左下角出發,在右上角結束。其次為了防止漫無目的的搜索,可以刪去那些向n軸方向或者m軸方向過分傾斜的路徑(例如,過分向n軸傾斜意味著R(m)壓縮很大而T(n)擴張很大,而實際語音中這種壓、擴總是有限的)。為了引入這個限制,可以對路徑中各通過點的路徑平均斜率的最大值和最小值予以限制。通常最大斜率定為2,最小平均斜率定為1/2。路徑的出發點可以選擇(n,m)=(1,1)點,也可以選擇(n,m)=(1,2)或(1,3)或(2,1)或(3,1)…點出發。前者稱為固定起點,后者稱為松弛起點。同樣,路徑可在(n,m)=(N,M)點結束,也可以在(n,m)=(N,M-1)或(N,M-2)或(N-1,M)或(N-2,M)…點結束。前者稱為固定終點,后者稱為松弛終點。
使用DTW算法為核心直接構造識別系統十分簡單,首先通過訓練得到詞匯表中各參考語音的特征序列,直接將這些序列存儲為模板。在進行識別時,將待識語音的特征序列依次與各參考語音特征序列進行DTW匹配,最后得到的總失真度最小且小于識別閾值的就認為是識別結果。該方法最顯著的優點是識別率極高,大大超過目前多數的HMM語音識別系統和VQ語音識別系統。但其最明顯的缺點是由于需要對大量路徑及這些路徑中的所有節點進行匹配計算,導致計算量極大,隨著詞匯量的增大其識別過程甚至將達到難以接受的程度,因此無法直接應用于大、中詞匯量識別系統。
4 結 語
以本系統為基礎開發了一種語音撥號系統,經過大量實驗表明,該系統電路運行穩定,且識別率可以達到90%。系統成本低,稍加改進就可把該語音識別模塊移植應用到各種系統設備中。







評論