一種基于密度的聚類的算法

3 算法性能及分析
對M-DBSCAN算法的性能作了測試,并與DBSCAN作了比較。所有的測試都在1臺PC機上進行,配置P4,2.0 GHz CPU,512 MB內(nèi)存,80 GB硬盤,算法用Matlab7.3實現(xiàn)。
首先用構(gòu)造的模擬數(shù)據(jù)對聚類結(jié)果進行驗證。圖2為DBSCAN算法在閾值半徑為20時得到的結(jié)果,明顯地將不同的三類作為一類輸出,形成了錯誤的類劃分;而在取同樣的初始閾值半徑時,圖3可以看出M-DBSCAN算法得到更好的聚類結(jié)果。
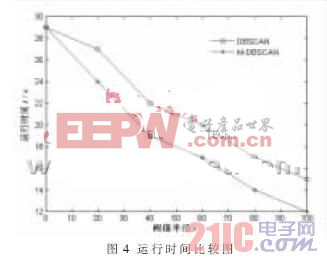
從圖4中可以看到兩種算法在SEQUOIA 2000數(shù)據(jù)庫上對不同數(shù)據(jù)量樣本的執(zhí)行時間的比較。算法M-DBSCAN比算法DBSCAN快得多,且隨著數(shù)據(jù)量的不斷增大,這種速度上的差別越來越大。表1為兩種算法的錯誤率比較圖,錯誤率為,N1為算法所得聚類數(shù)目,N2為實際聚類數(shù)目。表1中可看出,改進的M-DBSCAN算法錯誤概率普遍要小于DBSCAN的,表明改進后的算法減小了錯誤率,對處理大樣本集有較好的性能。
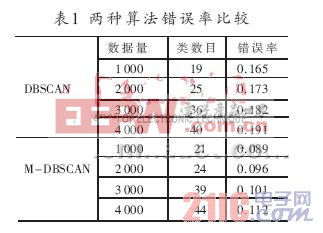
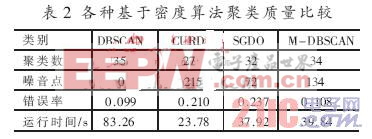
表2中的測試數(shù)據(jù)集來自Dr.JSrg Sander提供的仿照DBSCAN 中DataBase2生成的數(shù)據(jù)集DB2[8]。由表中可以看出,當數(shù)據(jù)規(guī)模為50 000時,雖然SGDO[7]處理噪音點的能力比M-DBSCAN強,但是從錯誤率和運行時間上M-DBSCAN比前兩者都有較大的改善。CURD雖然有較短的運行時間,但是存在大量的噪音點。
本文討論了一種將DBSCAN聚類算法進行改進的M-DBSCAN聚類算法,它克服了DBSCAN聚類算法不能處理大數(shù)據(jù)集的問題,并實現(xiàn)可以對閾值進行實時更改。試驗結(jié)果顯示,M-DBSCAN算法的準確性比DBSCAN算法要好,處理大數(shù)據(jù)集的速度更快。但是對于聚類數(shù)目的確定仍然是判斷是否超過某閾值才可算作某一類的標準,聚類數(shù)目與閾值的選擇有很大關(guān)系。因此如何自動確定聚類數(shù)目將是下一步工作的方向。







評論